UNAIR NEWS – Himpunan Mahasiswa Teknologi Sains Data (HIMA TESDA) Universitas Airlangga melangsungkan acara Data Science Training Center (DSTC). Pelatihan itu berlangsung secara online melalui zoom dengan topik “Natural Language Processing (NLP) Introduction and Project Examples by an Expert”. Acara itu berlangsung pada Jumat (15/09/2023).
DSTC merupakan program pelatihan yang bertujuan mewadahi mahasiswa, khususnya mahasiswa Teknologi Sains Data dalam meningkatkan wawasan seputar Data Science. Irfani selaku pemandu acara menjelaskan bahwa DSTC telah berlangsung secara rutin.
“DSTC sudah jalan sekitar 8 mingguan. Di setiap minggunya, kita membahas berbagai macam seputar data science. Mulai dari yang basic, seperti preprocessing data, algoritma machine learning, image processing, dan lain-lain,” tutur Irfani.
Edukasi Mahasiswa mengenai NLP Lewat DTSC
Sesuai dengan topiknya, HIMA TESDA menghadirkan pemateri yang ahli di bidang data dan AI, khususnya NLP. Pemateri tersebut adalah Affandy Fahrizain, alumni Sistem Informasi, Fakultas Sains dan Teknologi, Universitas Airlangga.
“Di kesempatan ini, aku akan sharing seputar NLP. Memang kesibukanku di Kata.ai lebih mengurus NLP dan saat S2 di Rusia mengurus tentang NLP juga. Jadi, ya, memang mainan sehari-hari gitu,” jelas Affan.
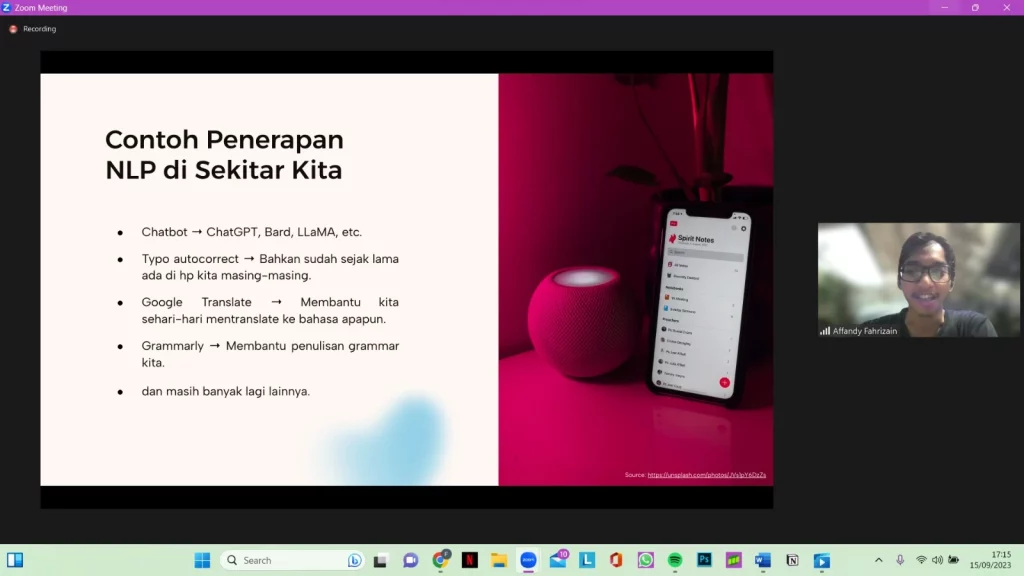
Affan menjelaskan bahwa NLP adalah cabang dari AI yang bertujuan untuk menganalisis data berupa teks dan menghasilkan sebuah insight dari data tersebut. Affan menyebutkan contoh penerapan NLP sebenarnya sudah sering menemani kita sehari-hari.
“Mungkin teman-teman tahu ChatGPT yang sedang ramai diperbincangkan, ya. Nah, itu adalah salah satu contoh NLP di level yang sangat tinggi. Ada juga contoh yang lebih sederhana, di antaranya Typo Autocorrect, Google Translate untuk menerjemahkan bahasa, Grammarly, dan masih banyak lagi,” sebut Affan.
Data Preparation untuk NLP
Affan menjelaskan 6 langkah mempersiapkan data untuk NLP yang sering ia gunakan. Pertama, data cleaning, dengan menghapus karakter yang tidak diperlukan. Kedua, tokenization, memecah teks input menjadi bagian kecil.
Ketiga, stemming atau mengembalikan kata ke bentuk dasarnya dengan menghapus imbuhannya. Keempat, stopword removal, menghapus kata-kata umum yang maknanya kurang berarti.
Kelima, vectorization, yakni mengubah teks yang telah terproses menjadi sebuah vektor atau embedding. “Langkah terakhir, modelling, melatih model menggunakan data yang telah diproses dan diubah menjadi vektor sebelumya,” jelasnya.
Tercatat dalam pelatihan ini, Affan membahas 4 poin, di antaranya adalah definisi NLP, contoh aplikasi NLP, embeddings, dan data preparation untuk NLP. Tidak hanya membahas mengenai teori, Affan turut memberikan penjelasan dengan coding project.
Pada akhir sesi pemaparan materi, Affan merekomendasikan beberapa online courses dan repositories yang bisa membantu peserta belajar mengenai NLP.
Penulis: Fath Tazkya Ernest Jamila
Editor: Nuri Hermawan