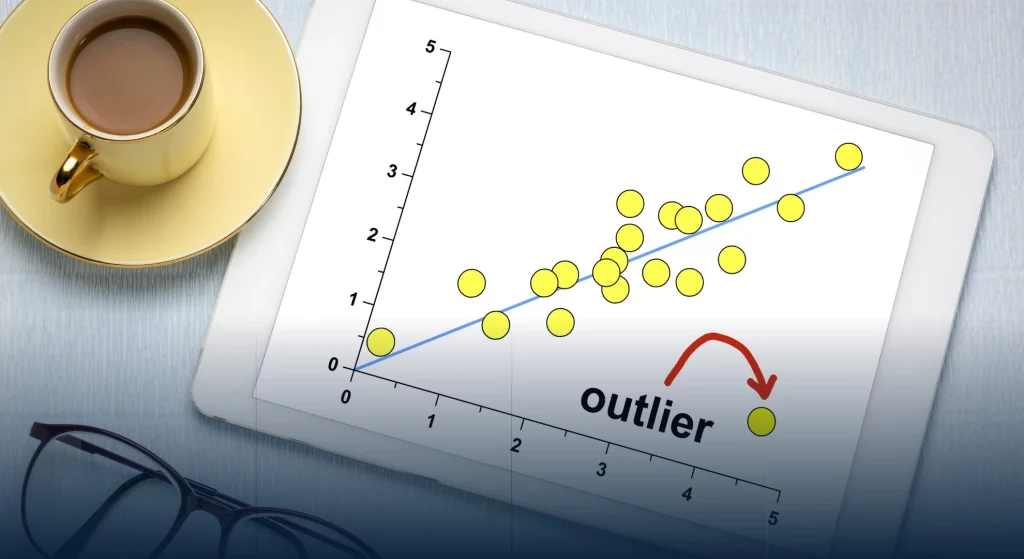
Dalam suatu pemodelan khususnya dalam bidang matematik maupun statistik, tidak jarang ditemukan data yang memiliki outlier. Data outlier adalah data yang memiliki nilai yang sangat berbeda atau ekstrem dibandingkan dengan sebagian besar data lainnya dalam suatu kumpulan data. Secara sederhana, outlier adalah data yang “terpisah” atau “jauh” dari pola umum data yang ada. Outlier bisa disebabkan oleh berbagai faktor, seperti kesalahan pengukuran, kesalahan input data, atau kejadian yang sangat langka. Contoh: Jika dalam suatu kelas terdapat nilai ujian yang sebagian besar berkisar antara 70 hingga 90, tetapi ada satu siswa yang mendapatkan nilai 30 atau 100, maka nilai tersebut bisa dianggap sebagai outlier karena sangat berbeda dari nilai-nilai lainnya. Mengapa penting mengenali outlier? Yang pertama, outlier dapat mempengaruhi analisis statistik, seperti rata-rata, standar deviasi, atau hasil dari model prediksi. Yang kedua, outlier perlu dihapus atau diperhatikan lebih lanjut, tergantung pada konteks dan tujuan analisis. Ada beberapa cara untuk mendeteksi outlier, seperti menggunakan grafik (misalnya boxplot), atau metode statistik seperti z-score atau interquartile range (IQR).
Outlier sering kali menjadi petunjuk yang sangat penting dalam analisis data. Meskipun mereka mungkin dianggap sebagai “kesalahan” atau data yang tidak biasa, mereka dapat mencerminkan fenomena yang jarang atau ekstrem namun relevan. Memahami dan mengidentifikasi outlier memungkinkan seorang ilmuwan statistik untuk menggali wawasan lebih dalam tentang karakteristik data tersebut. Kadang-kadang, outlier dapat merujuk pada suatu kejadian atau kondisi langka yang memiliki dampak besar, seperti data medis yang menunjukkan reaksi ekstrem terhadap pengobatan tertentu. Outlier dapat mempengaruhi banyak teknik statistik, terutama yang sensitif terhadap nilai ekstrim, seperti regresi linier atau mean. Dalam statistika, pengelolaan outlier menjadi penting untuk menghasilkan estimasi yang lebih akurat dan representatif. Jika outlier dibiarkan tanpa penanganan, hasil model bisa menjadi bias dan kurang valid. Oleh karena itu, ilmuwan statistik perlu mengidentifikasi dan menangani outlier untuk meningkatkan ketelitian analisis dan prediksi yang dihasilkan.
Dalam statistika, ada banyak teknik yang dirancang untuk menangani outlier, seperti analisis robust yang tidak terlalu dipengaruhi oleh outlier, atau metode transformasi data (seperti logaritma atau square root). Mempelajari cara mengatasi outlier memungkinkan ilmuwan statistik untuk menguasai dan menerapkan berbagai teknik lanjutan yang dapat memperbaiki kualitas analisis mereka. Ini berkontribusi pada pengembangan metode yang lebih baik dalam berbagai aplikasi statistik. Outlier dapat mempengaruhi hasil pengujian hipotesis, seperti uji t atau uji chi-square, dengan mengubah distribusi data dan nilai p. Dengan mengidentifikasi dan mengelola outlier, ilmuwan statistik dapat melakukan uji hipotesis yang lebih valid dan tepat. Hal ini memungkinkan pembuatan keputusan yang lebih baik dalam berbagai bidang, seperti ekonomi, medis, dan riset sosial.
Keilmuan statistika berfokus pada pengambilan keputusan berdasarkan data yang ada. Outlier yang tidak ditangani dengan benar bisa mengarah pada pengambilan keputusan yang tidak tepat, seperti memprediksi nilai yang sangat ekstrem yang tidak akan terjadi lagi di masa depan. Dengan mengelola outlier, keilmuwan statistika dapat lebih memahami data dan menghasilkan rekomendasi yang lebih baik, misalnya dalam bidang manajemen risiko, pengembangan produk, atau kebijakan publik. Studi tentang outlier juga mendorong pengembangan teori statistik yang lebih kuat. Ilmuwan statistik terus mengembangkan metode baru untuk mendeteksi, mengatasi, dan memahami outlier dalam berbagai konteks. Proses ini berkontribusi pada kemajuan keilmuan statistika, menghasilkan teknik yang lebih handal, robust, dan efisien untuk analisis data yang lebih baik. Outlier dapat menunjukkan adanya masalah dalam pengumpulan data, seperti kesalahan pengukuran, kesalahan pencatatan, atau bias dalam sampling. Mengidentifikasi dan mengatasi outlier juga dapat meningkatkan kualitas data yang digunakan dalam analisis. Hal ini berkontribusi pada peningkatan keilmuan dalam statistika karena data yang lebih bersih dan lebih representatif menghasilkan kesimpulan yang lebih valid.
Dalam bidang ilmu statistika, model regresi dibedakan menjadi model regresi linier dan model regresi non-linier. Lantas jika di dalam model regresi non-linier terdapat outlier bagaimana cara mendeteksi supaya akurat? Karena keakuratan penting di dalam pemodelan. Terdapat beberapa metode yang dapat digunakan untuk mendeteksi outlier di dalam model regresi non-linier. Beberapa diantaranya adalah Ramsey’s RESET Test dan Lagrange Multiplier Test (dibagi menjadi White Test dan Terasvirta Test). Dengan menggunakan uji simulasi pada beberapa model regresi non-linier dan dilakukan iterasi pada model-model tersebut, telah terbukti bahwa metode Terasvirta Test lebih unggul dibandingkan dengan metode lainnya. Dengan demikian tidak perlu khawatir lagi jika di dalam model regresi non-linier kita terdapat data outlier karena metode Terasvirta lebih robust dalam mendeteksi model regresi non-linier jika data kita mengandung outlier.
Penulis: Dr. Dwi Rantini, S.Si
Link: https://www.engineeringletters.com/issues_v32/issue_12/EL_32_12_12.pdf
Baca juga: Perspektif Global pada Big Data, Kecerdasan Buatan dan Akuntan Manajemen