Kesetaraan dalam mengakses AI dan kualitas pengembangan teknologinya seharusnya bukan didasarkan pada lokasi atau tingkat ekonomi suatu negara. Kemajuan chatbot berbasis AI seharusnya dinikmati secara adil di seluruh dunia, meskipun kemajuan teknologi juga menyebabkan akses yang tidak merata di berbagai bagian dunia karena pola diskriminasi, ketidaksetaraan, dan berbagai bias.
Informasi penaganan pasien di bidang onkologi-ginekologi membutuhkan akurasi tinggi dan aktual agar terhindari dari potensi morbiditas bahkan mortalitas. Pada studi ini kami mengekplorasi kemampuan AI-LLM dalam memberikan informasi medis yang konsisten dan tidak bias di berbagai negara/wilayah. Tujuannya adalah untuk mengidentifikasi potensi perbedaan dalam rekomendasi medis yang dihasilkan oleh AI, memastikan akses informasi kesehatan yang adil dan dapat diandalkan di seluruh dunia. Wawasan yang diperoleh dari temuan ini dapat diarahkan untuk peningkatan sistem AI, mendorong kesetaraan kesehatan global dan kepercayaan terhadap teknologi. Memahami perbedaan ini sangat penting untuk memajukan dan mengadopsi teknologi berbasis AI dalam praktik medis, yang pada akhirnya meningkatkan hasil dan pengalaman pasien secara global.
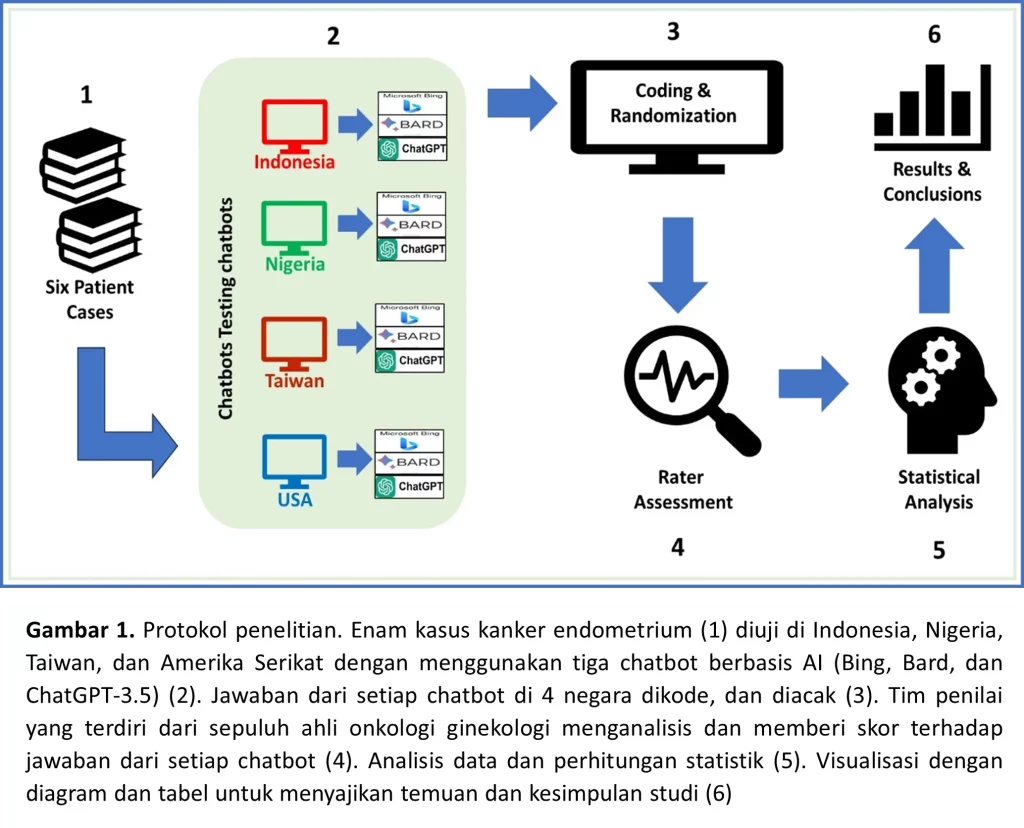
Tiga chatbot berbasis AI yang dapat diakses secara gratis (Bing, Bard, dan ChatGPT-3.5) digunakan dalam uji ini. Masing-masing chatbot diberikan input pertanyaan di 4 negara berbeda (Indonesia, Nigeria, Taiwan, dan Amerika Serikat) (Gambar 1). Skenario kasus pasien berasal dari data yang telah dipublikasikan dan kemudian diadaptasi menjadi soal kasus. Kami menggunakan pedoman dari The National Comprehensive Cancer Network (NCCN) sebagai standar perawatan untuk kanker endometrium, yang secara luas diterima sebagai pedoman pengobatan di banyak negara.
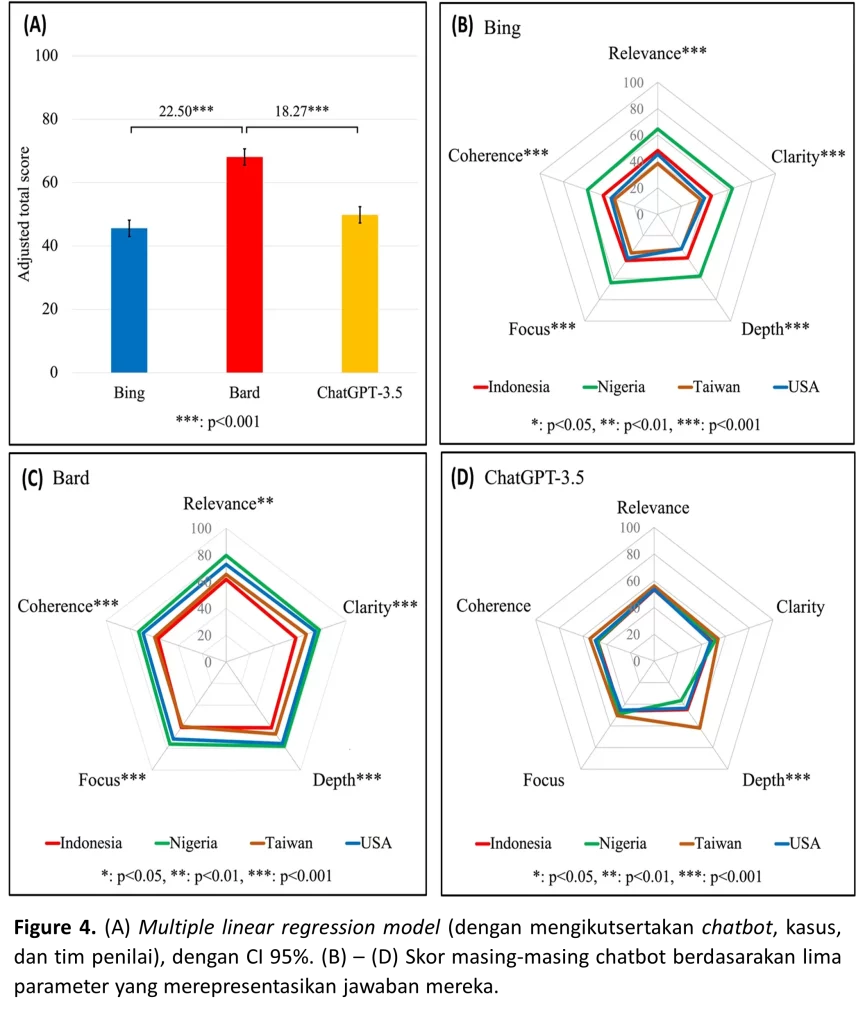
Nigeria menempati peringkat pertama berdasarkan kinerja gabungan dari ketiga chatbot, dengan peringkat pertama yang signifikan (p<0.001) dibandingkan Indonesia, Taiwan, dan Amerika Serikat (Gambar 2A). Bing di Nigeria tampil secara signifikan lebih tinggi (p<0.05) dibandingkan Bing di Indonesia, Taiwan, dan USA (Gambar 2B). Demikian juga, Bard di Nigeria tampil secara signifikan lebih tinggi (p<0.05) dibandingkan Bard di Indonesia dan Taiwan, tetapi tidak dibandingkan Bard di USA. Selain itu, Bard di USA tampil secara signifikan lebih tinggi daripada Bard di Indonesia (Gambar 2C). Kinerja ChatGPT-3.5 di Taiwan menunjukkan skor tertinggi tetapi tidak berbeda signifikan dengan tiga lokasi lainnya (Gambar 3D). Secara keseluruhan, hasil ini menunjukkan bahwa rekomendasi pengobatan yang diberikan oleh chatbot AI bervariasi secara signifikan berdasarkan lokasi.

Kami menganalisis skor chatbot berdasarkan lima parameter (relevansi jawaban, kejelasan, kedalaman, fokus, koherensi). Secara keseluruhan, di antara empat lokasi, Bard mencetak skor lebih tinggi dibandingkan ChatGPT-3.5 dan Bing (Gambar 3A) dengan selisih yang signifikan (p<0.001), menunjukkan bahwa Bard memberikan rekomendasi yang lebih baik. Analisis statistik kami juga menunjukkan bahwa Bing di Nigeria memiliki peringkat tertinggi pada semua parameter secara substansial (semua p<0.001) dibandingkan Indonesia, Taiwan, dan Amerika Serikat (Gambar 3B). Performa serupa juga terlihat pada Bard di Nigeria, yang mengungguli Bard di Indonesia (Gambar 3C). Sedangkan ChatGPT-3.5 di Taiwan mencapai skor tertinggi dalam “kedalaman”, di mana ia mengungguli tiga lokasi lainnya secara signifikan (p<0.001) (Gambar 3D). Hasil ini menunjukkan bahwa skor jawaban yang diberikan oleh chatbot AI bervariasi berdasarkan platform dan Bard mengungguli dua chatbot lainnya dalam studi ini.
Temuan ini menyoroti ketimpangan dan peluang disinformasi dalam kualitas penyajian informasi kesehatan berbasis AI berdasarkan negara. Hal ini menekankan perlunya lebih banyak penelitian dan pengembangan untuk menjamin akses yang setara ke informasi medis yang dapat dipercaya melalui teknologi AI.
Berdasarkan temuan dari studi ini, kami mendesak para pengembang AI untuk mengambil tanggung jawab sosial yang lebih besar dan berupaya lebih keras untuk mengurangi ketimpangan ketika menciptakan produk AI. Kami juga mendesak para regulator dan pembuat kebijakan industri AI untuk menetapkan kebijakan yang lebih ketat dalam mengatur industri AI, guna mencegah produk AI memperburuk ketimpangan yang ada. Identifikasi proaktif terhadap ketimpangan, strategi mitigasi yang ditargetkan, dan peningkatan transparansi dalam pelatihan model serta sumber data sangat penting untuk memastikan bahwa AI memberikan manfaat bagi semua orang, bukan hanya bagi beberapa pihak saja.
Penulis: Khanisyah Erza Gumilar
Link:
https://www.nature.com/articles/s41598-024-67689-0
https://doi.org/10.1038/s41598-024-67689-0
Baca juga: Menjelajahi Interaksi Antara Preeklampsia dan Kardiomiopati Peripartum